方法一:在线网站
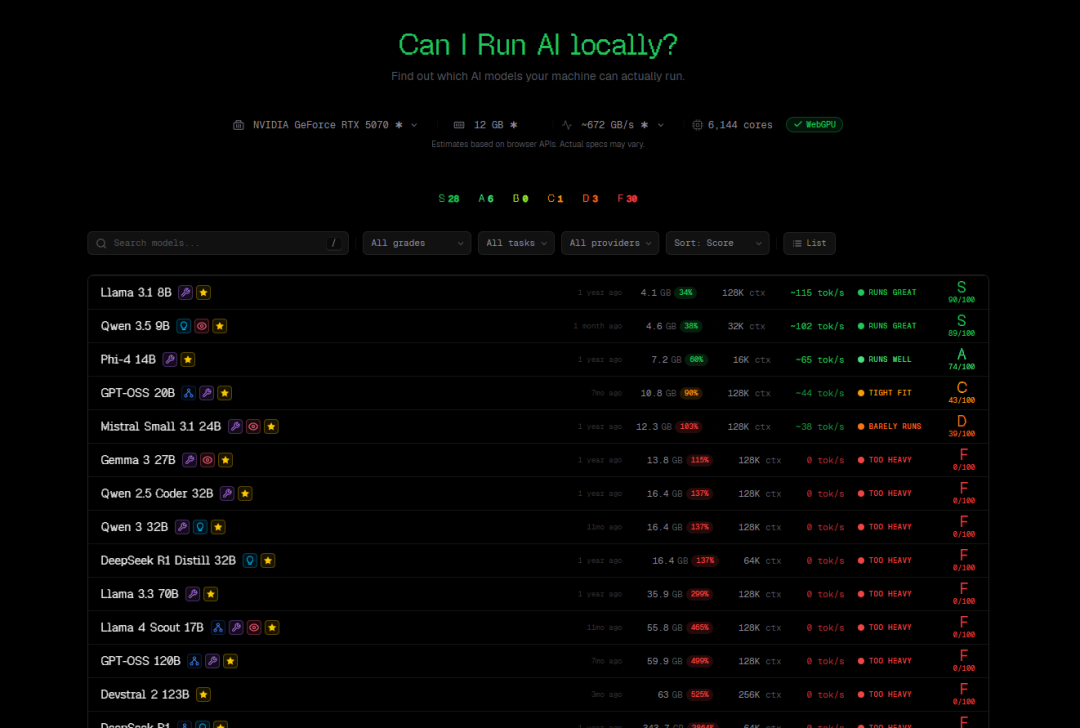
自动获取你的电脑配置,列出能运行的大模型,每秒的token等
缺点是有些自己魔改的显卡无法识别,只能推测GPU能力,无法判断CPU能力,仅供参考。
方法二:本地工具 llmfit
llmfit 是一个用 Rust 写的终端工具,专门解决"这个模型能在我电脑上跑吗"这个让人头疼的问题。
它是干什么的?
它能自动检测你的硬件(RAM、CPU、GPU),对每个模型从质量、速度、适配性、上下文长度四个维度打分,告诉你哪些模型能在你的机器上流畅运行。
目前数据库里收录了 157 个模型、覆盖 30 个提供商。
省去了"下载→跑不动→换量化版→再试"这种反复试错的痛苦。
安装方式
Linux / macOS 一行命令搞定:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh
Windows 用 Scoop:
scoop install llmfit
常用命令
几个核心命令如下:
# 启动交互式 TUI 界面(默认)
TUI 界面怎么操作
用上下方向键或 vim 风格的 J/K 键切换列表;按 Enter 查看模型详情;按 F 键可以循环切换筛选条件——All(全部)、Runnable(可运行)、Perfect(完美适配)、Good(良好)、Marginal(勉强能跑)。
量化选择逻辑
llmfit 会按照 Q8_0 → Q6_K → Q5_K_M → Q4_K_M → Q3_K_M → Q2_K 的顺序往下找,选出在你的显存里能塞下的最高质量量化版本。如果满上下文装不下,它还会尝试用一半上下文再试一次。对于 Mixtral、DeepSeek 这类 MoE 架构的模型,它也考虑了只有部分参数同时激活的特性。
需要注意的局限
速度估算是计算出来的,不是实测值;"质量"评分基于参数量和模型声誉,不是真实评测;模型数据库也是静态的,昨天刚发布的新模型可能还没收录。
总体来说,如果你喜欢在本地跑 LLM,llmfit 能帮你快速缩小选择范围,非常实用。
