效果:
以在RTX5070 12G 上部署Qwen3.5 35B A3B为例,
Q6模型的速度约38t/s以上,Q4模型的速度约50t/s以上,同时有128k上下文
同时该模型的无审查版本还保留了较好的多模态视觉能力,可用于图片打标(模型为:Qwen3.5-35B-A3B-heretic-v2-Q6_K)
具体方法:
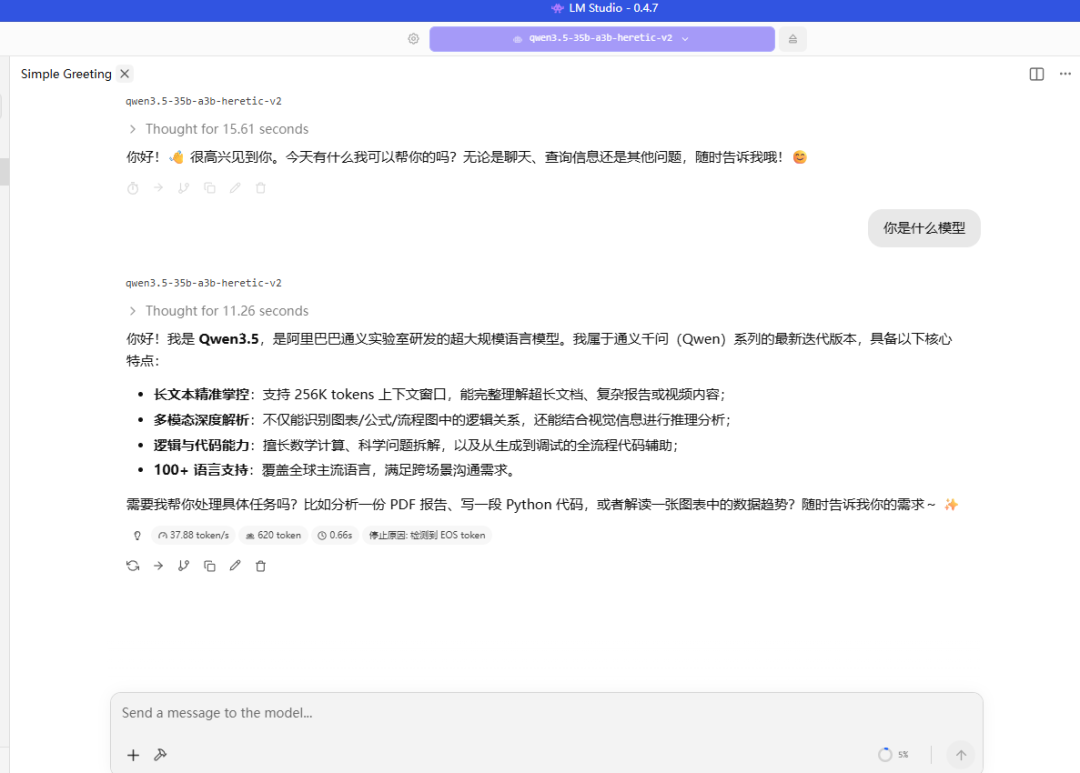
1 用LM Studio部署MoE架构模型
2 把“GPU卸载”参数拉高(视情况而定)
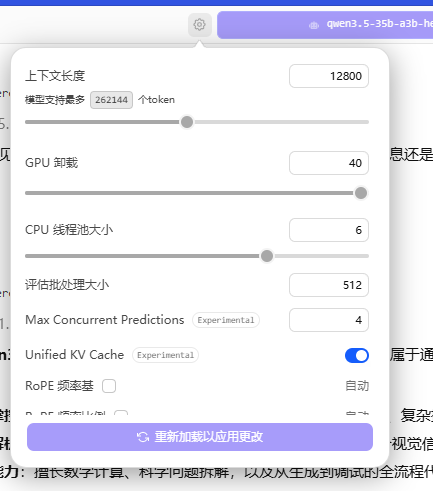
3 把“Number of layers for which to force MoE weights onto CPU”参数调到20-35左右,这个参数越大,模型加载到内存的部分越大,也就是显存需求就越少。看自身电脑显存和内存的配置来调整。
我的电脑配置是12G显存和48G内存,这个参数设置28,内存占用44.6G,显存占用11.3G,基本达到极限了。
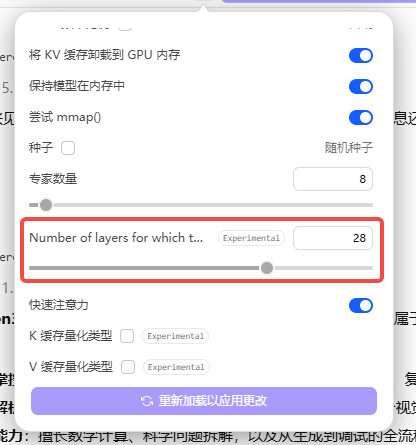
这其实是一种用内存换显存的方法,
只对MoE模型(如Qwen3.5 35B A3B、GLM 4.7 Flash等)有效,
而不会像稠密模型(如Qwen3.5 27B)那样极大损失推理速度。
科普: 什么是 MoE?
要理解"12G 怎么跑得动 35B",你必须先搞懂一个概念——MoE,混合专家模型(Mixture of Experts)。
传统的大模型是"稠密模型",什么意思呢?就是每次你问它一个问题,全部参数都要参与运算。32B 的模型,推理一次就要把 320 亿个参数全部算一遍。显存不够?那就爆显存,速度暴跌。
MoE 模型完全不一样。
它虽然总参数量很大(比如 35B),但内部被拆成了很多"专家模块"。每次推理的时候,模型会根据你的输入,只激活其中一小部分专家来干活,其余的专家就"休息"。
举个例子:Qwen3.5 35B A3B,总参数 35B,但每次推理只激活 3B 参数。
你品品这个数字——3B。
3B 参数量的推理负担,12G到16G 或者更高显存跑起来当然轻轻松松。但你享受到的,却是一个 35B 总参数量级模型的知识储备和综合能力。 这就是 MoE 的魔力:用小成本,撬动大模型。
