
当我们说"大模型在推理"时,里面究竟发生了什么?有人把整个过程做成了一部可以暂停、旋转、逐帧观看的3D动画。
我们每天都在用大模型,但如果有人问你:当你输入一句话,模型内部到底经历了什么?
大多数人的回答大概是:呃……Transformer?注意力机制?然后就没了。
不是因为你不想懂,而是因为这些概念太抽象了。论文里的公式看得人头皮发麻,教程里的架构图画得像地铁线路图。缺的不是知识,而是一种能让人"看见"的方式。
最近发现的一个网站,做到了这一点。
一个能"看见"大模型推理的网站
网站叫 LLM-Visualized(llm-visualized.com),是一个交互式的3D/2D可视化项目。
它做的事情说起来很简单:把GPT-2模型处理一句话的完整过程,一步一步、一层一层地用动画展示出来。
不是画示意图,不是放PPT,而是把模型真实的前向传播过程(forward pass)提取出来——每一个向量的值、每一个注意力分数、每一层的变换——然后用3D场景和2D矩阵两种方式同时呈现。
你可以暂停、快进、跳到某一层,甚至旋转镜头从不同角度观察数据在模型中的流动。
用的是GPT-2的124M参数版本。虽然不是当今最强的模型,但它和GPT-3、GPT-4共享同一套Transformer架构。看懂了GPT-2的推理过程,你就抓住了所有主流大模型的骨架。
它到底展示了什么?
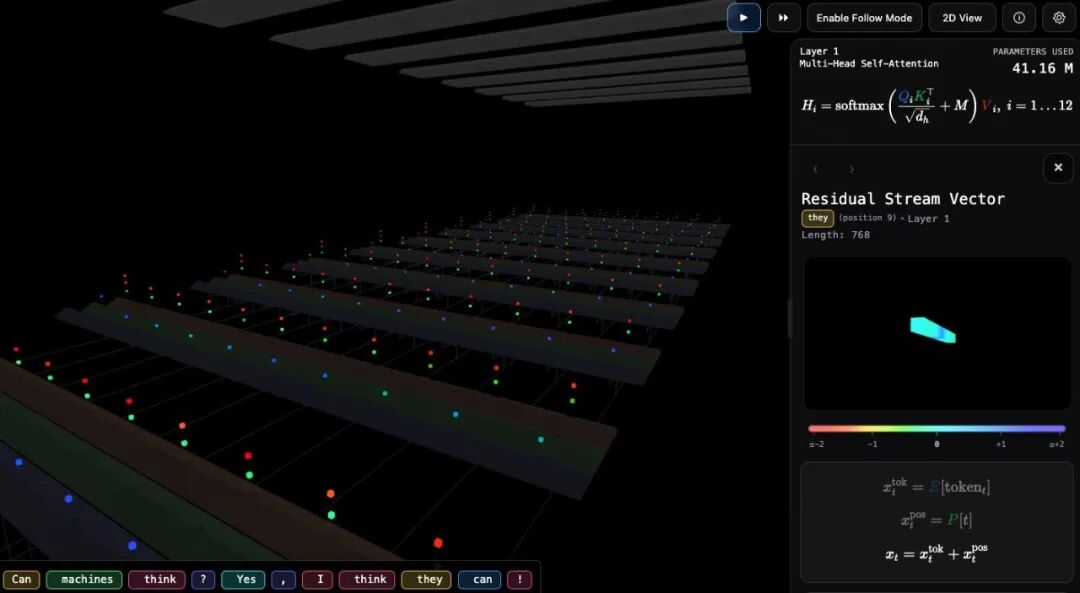
打开网站,你会看到一个由Three.js构建的3D场景。一句提示词被送入模型后,整个推理过程就像一条流水线一样展开。
第一站:Token嵌入
输入的文字首先被拆分成token,然后通过嵌入矩阵(Embedding Matrix)转化为向量。这一步是所有大模型的起点——把人类语言翻译成模型能理解的数字表示。
在网站上,你能看到每个token对应的向量被渲染成彩色的条带。作者的做法是每隔64个维度采样一个值,用这些值来决定颜色。比如一个768维的向量,会被采样出12个值,对应12种色调。虽然是简化的呈现,但足以让你直观感受到"向量"到底长什么样。
第二站:12层Transformer Block
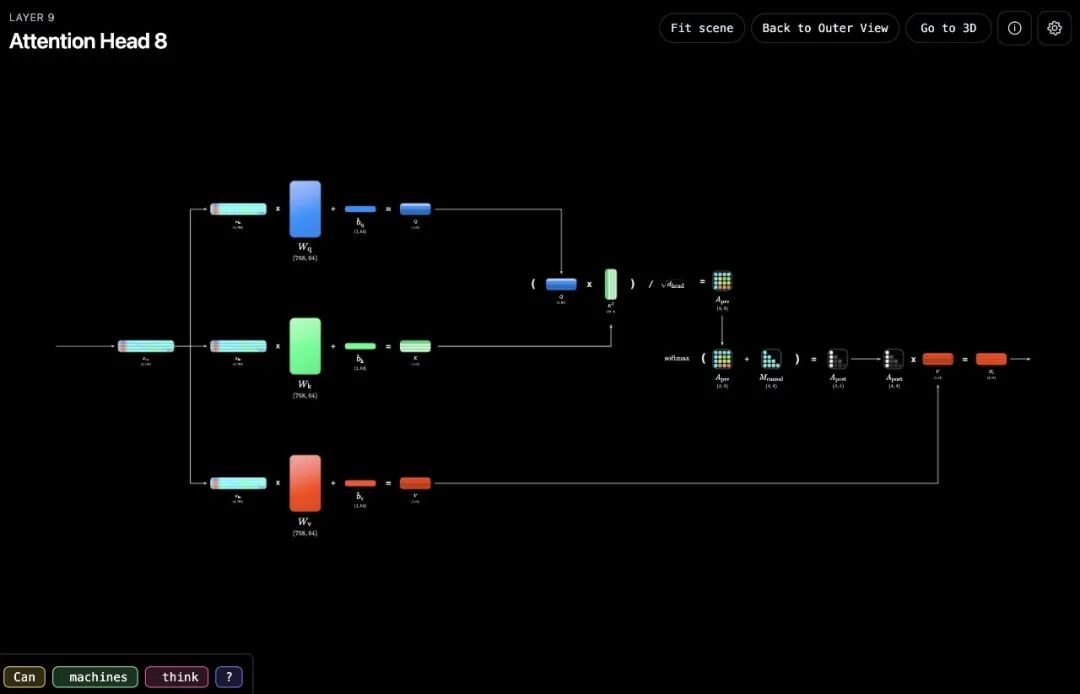
GPT-2(124M)有12层Transformer Block,每一层都包含多头自注意力(Multi-Head Self-Attention)和前馈神经网络(FFN)。
这是整个可视化最精彩的部分。
在3D视图中,Y轴代表层数,Z轴代表上下文维度。你能看到数据像信号一样从第1层向第12层逐层传递,每经过一层都会被注意力机制重新加权、被前馈网络进一步变换。
切换到2D视图,同样的信息以矩阵形式展示。你可以点开某一层的注意力分数矩阵,看到每个token对其他token的关注程度——哪些词在"看"哪些词,一目了然。
第三站:输出预测
经过12层处理后,最终的向量会被映射回词汇表,生成每个候选token的概率分布。概率最高的那个,就是模型的预测输出。
整个流程走下来,你会真切地理解:大模型不是在"理解"语言,而是在做一连串极其精密的矩阵运算。 每一层都在提取不同层次的特征,注意力机制决定了信息如何在token之间流动。
几个值得一提的细节
KV Cache可视化。 网站支持开启KV Cache模式,展示模型在生成多个token时如何复用之前计算过的Key和Value,避免重复计算。这是大模型推理加速的核心技术之一,平时只在论文里看到公式,这里你能直接看到缓存是怎么被存储和调用的。
可交互的注意力矩阵。 点击任意一个注意力头,可以查看完整的注意力分数矩阵。矩阵的每个格子代表一个Query token对一个Source token的关注权重,用颜色深浅直观呈现。你能清楚看到,在某些层里,模型会格外关注句子开头的token;在另一些层里,它更关注相邻的上下文。
Dev模式。 在设置里打开Dev模式,点击场景中的任何向量,侧边栏会显示采样出的具体数值和对应的维度位置。适合想深入研究的人。
键盘控制。 空格暂停/播放,方向键控制3D镜头旋转,WASD平移,加减号缩放。操作逻辑和游戏类似,上手很快。
它解决了什么问题?
关于Transformer的教学资源其实不少。Jay Alammar的《图解Transformer》是经典入门读物,3Blue1Brown的神经网络系列深入浅出,Brendan Bycroft也做过一个广受好评的LLM 3D可视化项目。
LLM-Visualized的独特之处在于:它展示的是真实模型在处理真实文本时的真实数据,而不是简化后的示意动画。
那些向量的颜色来自GPT-2实际计算出的数值,注意力矩阵里的分数也是从模型中提取的真实权重。这意味着你看到的不是"大概是这样",而是"就是这样"。
对于几类人来说,这个网站特别有价值:
AI初学者——论文和教程里的Transformer架构图是静态的、抽象的,而这里的3D动画让你第一次能"走进"模型内部,跟着数据流走一遍完整的推理链路。
开发者和工程师——如果你在做模型推理优化,亲眼看到KV Cache的工作方式、注意力分数的分布模式,比读十篇技术博客都来得直观。
向别人解释AI的人——无论是给老板汇报、给学生上课,还是写科普文章,打开这个网站现场演示,比任何PPT都有说服力。
还在持续进化
作者在项目说明中提到了一些未来计划:增加更多可选的提示词和生成样例;开放数据提取脚本,让用户可以可视化自己输入的文本的前向传播过程;优化性能和交互体验。
项目目前部署在Vercel上,用Three.js构建3D场景,整体体验流畅。在笔记本浏览器上跑得也不错,不需要高端显卡。
写在最后
Richard Feynman说过一句广为流传的话:"What I cannot create, I do not understand."
这个网站把这句话反过来用了一次:What I cannot see, I cannot understand.
大模型的内部运作不应该只是论文里的公式和架构图里的方块。当你亲眼看到一个768维的向量在12层Transformer中被层层加工,看到注意力机制如何决定每个词该"关注"谁,你对这项技术的理解会从"知道"变成"懂了"。
打开浏览器,访问 llm-visualized.com,花20分钟,看一次大模型的"思考"过程。
这可能是你理解AI最高效的20分钟。
